如何解读线性回归的结果?
04 Mar 2020线性回归是一种简单又强大的统计模型,可用于检测两个或者多个变量之间的线性关系。常用统计软件包括R,Python,SPSS等都有相应模块帮助我们轻松建立线性回归模型。但面对软件给出的一长串统计结果时,很多朋友不知道如何解释这些数字,从而无法对模型的有效性给出合理诊断。
通过阅读本文,你将能理解报告中核心数字所代表含义,更精确的阐释回归分析结果。
一般来说,回归分析报告主要包含以下三个部分:
1.模型摘要
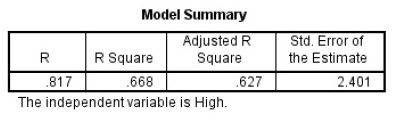 模型概要
模型概要
摘要告诉我们模型的拟合性如何。表中的 \(R\) 叫相关系数, \(R^2\),Adjusted \(R^2\)叫校正决定系数,这三个指标统计意义相似,通常情况下只看\(R^2\) 就好了。比如 \(R^2=0.668\)表示回归模型可以解释因变量\(y\)的方差的 \(66.8\%\),拟合性还是不错的。
2.方差分析
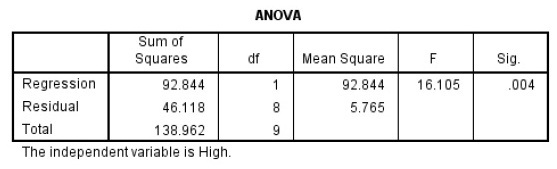 ANOVA分析
ANOVA分析
方差分析的本质是检测 \(R^2\) 是否显著大于0。重点在表格最后两列的F统计值和\(Sig.\) (表示对应 \(p\) 值)。上表中 \(p=0.004<0.05\) , 假设检验有效,表明\(R^2\)显著大于0,也就是说至少有一个自变量和 \(\hat{y}\)存在显著的线性关系,因此我们的回归模型有统计学意义。
3.回归系数
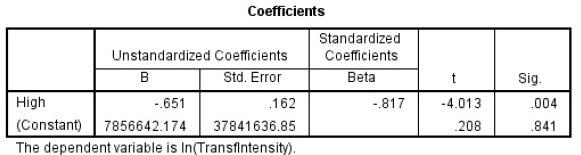 回归系数
回归系数
回归系数表格列出了输出模型的偏回归系数估计值(本例只有自变量 \(High\)和常数项 \(Constant\)。表格给出了非标准化系数(Unstandardized Coefficients),标准化系数(Standardized Coefficients),以及各偏回归系数(是否为0)的t检验结果。
非标准化系数表示各变量的拟合系数,比如 \(High\)的系数为\(-0.651\),表示\(High\)每增加一个单位,\(\hat{y}\)将减小\(0.651\)个单位。\(Constant=856642.174\)表示\(High\)取0时,\(\hat{y}\)的预测值为\(7856642.174\)。最后两列分别为\(t\)值和\(p\)值,我们只要看非常数项的 \(p\) 值就好了,\(p<0.05\)表示该偏回归系数统计有效,否则统计无效。
综上,我们可建立回归方程
\[\hat{y}=-0.651*High+7856642.174\]特别说明:纳入哪些自变量进行回归预测是由研究者根据专业和经验结合统计结果决定,而不是单单根据统计结果来决定。当自变量较多需要进行筛选自变量时,不同的筛选方法、不同的纳入剔除标准,也会得到完全不同的结果,入选的不一定是最好的,没有纳入的也未必没有统计学意义。